로지스틱 회귀란
독립 변수의 선형 결함을 이용해 사건의 발생 가능성을 예측하는 데 사용되는 통계 기법으로 독립 변수의 선형 조합을 로지스틱 함수를 사용해 종속 변수에 대한 확률 점수로 변환한다.
또한, 로지스틱 함수는 시그모이드 함수라고도 하며 'S'자 모양 곡선으로 입력 값을 '0'과 '1' 사이의 값으로 출력한다.
로지스틱 회귀 모델은 독립 변수의 계수(기울기 매개 변수)를 추정한다.
이 계수는 해당 독립 변수의 한 단위 변화에 대한 종속 변수의 로그 오즈 변화를 나타내며, 다른 모든 변수를 일정하게 유지하는 동안 적용된다.
로지스틱 회귀의 목적은 종속 변수와 독립 변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다. 이는 선형 회귀 분석과 유사하나, 선형 회귀 분석과 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 분류 기법으로도 볼 수 있으며 시그모이드 패턴을 따르는 연속 결과 모델링에도 사용될 수 있다.
로지스틱 회귀의 종류
- 로지스틱 회귀
- 종속 변수의 결과가 2개의 카테고리로 존재하는 경우(ex ) 예, 아니오)
- 로지스틱 함수가 '0'과 '1' 사이의 값으로 계산되더라도 답을 가장 가까운 값으로 반올림/반내림 한다.
- 다항 로지스틱 회귀 또는 분화 로지스틱 회귀
- 결과의 수가 유한하다는 전제 하에 종속형 변수가 3개 이상의 카테고리로 분류되는 경우 (ex ) 맑음, 흐림, 비)
- 결과 값을 '0'과 '1' 사이의 다른 값에 매핑하는 방식으로 작동한다.
- 0.1, 0.11, 0.12 등 연속된 데이터의 범위를 반환할 수 있으므로, 출력값을 가능한 가장 가까운 값으로 그룹화한다.
- 서수 로지스틱 회귀 또는 순서형 로짓 모델
- 복수의 범주이면서 순서가 존재하는 경우
- 숫자가 실제 값이 아닌 순위를 나타내는 문제를 풀기 위한 특수한 유형의 다항 회귀 분석이다.
로지스틱 회귀와 선형 회귀의 차이
둘 다 회귀라는 단어가 들어가 있기 때문에 두 개 이상의 변수간의 관계를 중심으로 분석하는 방법이지만 선형 회귀는 값을 추측하는 것이고 로지스틱 회귀는 분류(0, 1)하는 것이다.
말로 쉽게 하자면 '10년 후의 주식이 얼마일까요?'와 '10년 후에 주식이 오를까요?'의 차이라고 볼 수 있다.
확실히 나누어 본다면 아래와 같다.
- 이항형인 데이터에 적용하였을 때 종속 변수 y의 결과가 범위[0, 1]로 제한된다.
- 조금 더 자세한 설명 : 대상이 되느니 데이터의 종속 변수 y의 결과는 0과 1 두 개의 경우만 존재하는데 반해, 단순 선형 회귀를 적용하면 범위[0, 1]을 벗어나는 결과가 나오기 때문에 오히려 예측의 정확도만 떨어뜨린다.
- 종속 변수가 이진적이기 때문에 조건부 확률(P(y\x))의 분포가 정규분포 대신 이항 분포를 따른다.
로지스틱 회귀 작동 과정

- 선형 결합
- 입력 변수들의 선형 결합을 계산한다.
- 함수 : z = β₀ + β₁x₁ + β₂x₂ + ... + βₖxₖ
- z는 선형 결합을 나타내며, 확률 값을 계산하는데 사용된다.
- β₀ + β₁ + β₂ + ... + βₖ는 가중치 또는 계수를 나타내며, 이 값들은 훈련 데이터로부터 학습된다.
- x₁, x₂, ..., xₖ는 입력 변수들의 값이다.
- 로지스틱 함수(시그모이드 함수)
- 선형 결합 z는 로지스틱 함수(시그모이드 함수)에 입력으로 들어간다.
- 함수 : σ(z) = 1 / (1 + e^(-z))
- σ(z)는 로지스틱 함수를 나타내며, 확률 값을 출력한다.
- e는 자연 상수다.
- z는 선형 결합의 값이다.
- 임계값 설정
- 로지스틱 함수의 출력 값을 사용해 이진 분류를 수행한다.
- 보통 0.5와 같은 임계값을 설정하여 확률 값이 임계값보다 크면 양성, 작으면 음성으로 예측한다.
- 모델 훈련
- 로지스틱 회귀 모델에 훈련 데이터를 사용하여 가중치를 최적화 한다. 이를 위해 주로 로그-우도(log-likelihood, 최대가능도 방법) < 로그-우도란? '~이 일어날 확률을 뜻한다.' 로지스틱 회귀 모델 훈련에서는 분류를 하기 위해 임계값을 기준으로 양성 클래스와 음성 클래스에 데이터들을 잘 분류해내야 하기 때문에 로그-우도를 최대화하는 방향으로 최적화 시켜야 한다. >를 최대화 하는 방향으로 최적화 한다.
- 경사 하강법(Gradient Descent)과 같은 최적화 알고리즘을 사용하여 가중치를 업데이트하면서 모델을 학습시킨다.
- 성능 평가
- 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수(F1-Score) 등 다양한 평가 지표를 사용해 모델이 얼마나 잘 분류하는지 평가한다.
로지스틱 회귀 분석 분류 성능 평가 지표
일반 선형 회귀 분석과 다르게 로지스틱 회귀로 넘어오면 성능을 평가하는 '분류 성능 평가 지표'가 있다.
로지스틱만 있는 이유는 연속형 실수 값을 가지는 레이블을 분석하는 Regression의 경우 연속형 실수의 값을 맞추기 불가능하기 때문이다. 반면, 이진 분류는 맞다 / 틀리다 둘 중 하나로 나뉘기 때문에 머신 러닝의 효능을 평가할 수 있는 방법이 있다.
평가 지표는 여러가지가 있으나, 대표적인 세 가지를 소개한다.
- 정밀도(Precision) : 모델이 'true'라고 분류한 것 중 실제 'true'인 것을 맞춘 비율
- 재현율(Recall) : 실제 'true'인 것 중 모델이 'true'로 예측한 비율
- 정확도(Accuracy) : 모델이 예측한 것이 맞춘 비율

위 테이블은 confusion matrix라고 불리는 평가 지표에 쓰이는 요소를 담고 있는 테이블이다.
특징을 몇 가지 꼽아보면 아래와 같다.
- 모델의 관점에서 테이블을 읽는 것이 중요하다(열 방향으로 읽음)
- 모델이 True라고 예측한 행의 값들을 보면 뒷 단어가 positive인 것을 알 수 있다.
- 모델이 negative라고 예측한 행의 값들을 보면 뒷 단어가 negative인 것을 알 수 있다.
- 실측 데이터의 관점에서 테이블을 읽는 것이 중요하다(행 방향으로 읽음)
- 모델의 예측값이 실측 데이터와 일치한다면 True라고 표기되는 것을 알 수 있다.
- 모델의 예측값이 실측 데이터와 다르다면 False라고 표기되는 것을 알 수 있다.
실제 머신 러닝에서는 앞 글자를 따서 TP, FP, TN, FN으로 표기한다.
그리고 앞서 언급했던 정확도(Accuracy), 정밀도(Precision), 재현율(Recall)을 confusion matrix 요소로 표현하면 아래와 같다.

위의 수식을 이용해 평가할 때 유의해야하는 것은 아래와 같다.
- 정확도(Accuracy) : 내가 맞다, 틀리다로 예측한 것 중 맞은 개수에 대한 비율이 나와있어 가장 직관적이지만 큰 단점이 있다. 바로 불균형한 레이블 값 분포에서 머신 러닝 성능을 평가하면 적합한 평가 지표로 활용이 되지 않는다는 점이다.
- 재현율(Recall)과 정밀도(Precision)는 '반비례' 관계에 있다.
위의 수식의 결괏값을 해석하는 방향은 아래와 같다.
- 정확도(Accuracy) : 예측이 정답과 얼마나 정확한가?
- 재현율(Recall) : 찾아야 할 것 중에 실제로 찾은 비율은?
- 정밀도(Precision) : 예측한 것 중 정답의 비율은?
추가로 로지스틱 회귀 분석 분류 성능 평가 지표 중 F1 Score도 있는데 이 지표는 정밀도와 재현율의 평균을 구한다.
F1 Score는 정밀도(Precision)와 재현율(Recall)의 조화 평균으로 수식은 아래와 같다.
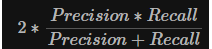
F1 Score는 정밀도(Precision)와 재현율(Recall)을 조합해 하나의 통계치를 반환하는데 여기서 일반적인 평균이 아닌 조화 평균을 계산한다. 왜냐하면 정밀도(Precision)와 재현율(Recall)이 '0'에 가까울수록 F1 Score도 동일하게 낮은 값을 갖도록 하기 위해서다.
예를 들어 재현율(Recall)이 '1'이고 정밀도(Precision)가 '0.01'로 측정된 모델이 있는 경우 정밀도(Precision)가 매우 낮아 F1 Score에도 영향을 미치게 된다. 그래서 일반적인 방법으로 평균을 구하게 되면 '0.505'로 값이 높지만 조화 평균으로 계산하면 '0.019'로 낮게 계산되는 모습을 볼 수 있다.

로지스틱 회귀 코드 공부
https://github.com/DIB-PP/Machine-Learning
GitHub - DIB-PP/Machine-Learning
Contribute to DIB-PP/Machine-Learning development by creating an account on GitHub.
github.com
참고 사이트
- https://ko.wikipedia.org/wiki/%EB%A1%9C%EC%A7%80%EC%8A%A4%ED%8B%B1_%ED%9A%8C%EA%B7%80
- https://velog.io/@zlddp723/%EB%A1%9C%EC%A7%80%EC%8A%A4%ED%8B%B1-%ED%9A%8C%EA%B7%80Logistic-Regression
- https://m.blog.naver.com/quovadis34/221805694858
- https://spaceofna.com/%EB%A1%9C%EC%A7%80%EC%8A%A4%ED%8B%B1-%ED%9A%8C%EA%B7%80-logistic-regression/
- https://rphabet.github.io/posts/metric/
- https://sungin.tistory.com/133
'공부일기 > Machine-Learning' 카테고리의 다른 글
| K-최근접 이웃(K-Nearest Neighbors, K-NN) (0) | 2024.07.17 |
|---|---|
| 서포트 벡터 머신(Support vector machine) (0) | 2024.07.17 |
| 랜덤 포레스트(Random forest) (0) | 2024.07.15 |
| 결정 트리(Decision Tree) (0) | 2024.07.12 |
| 선형 회귀(Linear regression) (0) | 2024.07.10 |