앙상블 학습
여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법이다.
weak classifier(약한 분류)들을 결합하여 strong classifier(강한 분류)를 만드는 것이다. 결정 트리에서 과적합(overfitting)되는 문제를 앙상블에서는 감소시킨다는 장점이 있다.
앙상블 기법에는 보팅(voting), 배깅(bagging), 부스팅(boosting), 스태킹(stacking)이 있다.
보팅(voting)
여러 머신러닝 알고리즘을 같은 데이터 세트에 대해 학습하고 예측한 결과를 투표하여 최종 예측 결과를 선정하는 방식이다.
하드 보팅(hard voting)

- 각 분류기가 최종 클래스를 정하면 더 많은 클래스를 최종 클래스로 결정한다.
- 다수결의 원칙과 비슷하다.
소프트 보팅(soft voting)

- 각 분류기마다 각 클래스의 확률을 정하고 확률들의 평균값이 큰 값을 최종 클래스로 결정한다.
- 일반적으로 소프트 보팅의 성능이 더 좋아 많이 사용된다.
배깅(bagging)
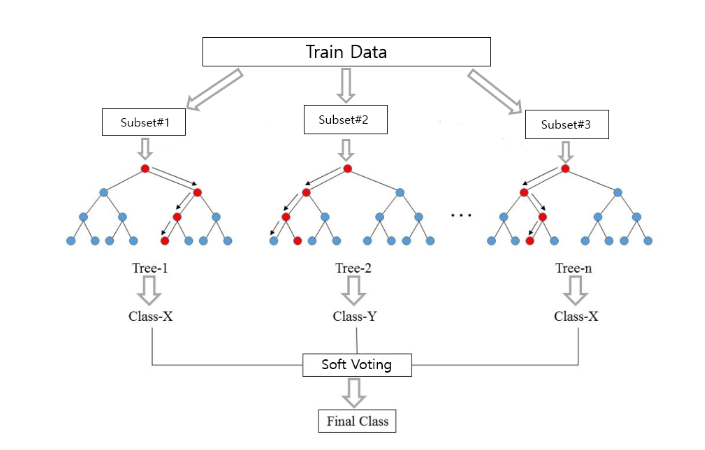
같은 모델에서 여러 개의 분류기를 만들어 보팅(voting)으로 최종 결정하는 알고리즘이다. 다르게 말하자면 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과물을 집계한다.
샘플을 뽑을 때는 랜덤으로 뽑으며, 랜덤은 '데이터를 랜덤 하게 샘플링하는 것'과 '개별 모델이 트리를 구성할 때 분할의 기준이 되는 특징(feature)을 랜덤 하게 선정한다'는 2개의 의미를 지닌다.
앙상블 모델 중 비교적 빠른 수행 속도와 다양한 영역에서 높은 예측 성능을 보이며, 결정트리 기반인 만큼 직관성이라는 장점이 있다. 또한, 학습 데이터가 충분하지 않더라도 충분한 학습 효과를 주어 높은 bias(편향)나 과소적합(underfitting) 문제 또는 높은 분산으로 생기는 과적합(overfitting) 문제를 해결하는데 도움을 준다.
분류와 회귀 모두 사용이 가능하며, 배깅의 대표적인 알고리즘은 랜덤 포레스트이다.
부스팅(boosting)
여러 개의 약한 학습기를 순차적으로 학습, 예측하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해 가며 점진적으로 학습하는 방식이다.
부스팅은 복원 랜덤 샘플링을 활용해 다수의 샘플 N개를 만들고 하나의 모델을 설정해 샘플 1부터 학습을 진행한다.
이때 부스팅 알고리즘은 샘플 1에서 잘 분류하지 못한 데이터에 가중치를 주고 샘플 2로 넘긴다. 이 방식으로 마지막 샘플까지 순차적으로 진행한다. 마지막 샘플까지 학습을 진행했다면 이제까지 학습된 모든 모델을 모두 고려해 최종 평가를 진행한다.
종류는 크게 AdaBoost와 GBM이 있고, GBM을 더욱 발전시킨 XGBoost와 LightGBM, Catboost이 있다.
AdaBoost(Adaptive Boosting)
AdaBoost의 작동 원리는 부스팅의 작동 원리에서 마지막 최종 평가 부분이 다르다.
부스팅은 가중치를 갱신한 모델을 최종 평가에 같이 고려하지만 AdaBoost에서는 개별 모델에 가중치를 별도로 주는 개념이 추가된 방식이다.
AdaBoost의 과정은 아래와 같다.
- 데이터 N개의 개별 가중치를 1/N으로 초기화한다.
- 오분류된 데이터들의 가중치 합을 최소화하는 약한 모델을 찾는다.
- 2번에서 나온 약한 모델의 오분류된 데이터 가중치의 합을 통해 모델의 개별 가중치를 찾는다.
- 모델과 모델 가중치를 이용해 최종 모형을 구성한다.
- 오분류 데이터에는 가중치를 증가하고 아니라면 감소시켜 데이터 가중치를 초기화한다.
- 2번부터 5번을 반복한다.
GBM(Gradient Boosting)
GBM은 오차를 미분한 경사도(gradient)를 줌으로써 모델을 보완하는 방식이다.
GBM에서 사용되는 가장 핵심적인 방법은 gradient descent, 경사하강법이다.
경사하강법은 손실 함수(loss fuction)를 정의하고 이의 미분값이 최소가 되도록 하는 방향을 찾고 접근하는 방식이다.
GBM의 과정은 아래와 같다.
- 초기값으로 상수함수를 적용한다.
- 손실 함수를 최소화하는 경사도(gradient)를 구한다.
- 경사도(gradient)를 모델의 타겟 값으로 사용해 경사도(gradient)를 고려한 학습을 진행한다.
- 학습률을 더해 최종 모형을 만든다
- 2번에서 4번 과정을 반복한다.
GBM에는 GBM을 더욱 발전시킨 XGBoost와 LightGBM, Catboost이 있다.
- XGBoost
- 최적화된 그래디언트 부스팅 구현이 가능한 파이썬 라이브러리다.
- 빠른 속도, 확장성, 이식성이 특징이다.
- 이전 모델이 과소적합한 샘플에 가중치를 줘서 다음 모델에서 예측 정확도를 높이는 방식으로 모델을 보완해 가는 부스팅 기법을 사용한다.
- GBM보다 빠르고 조기종료가 가능하며 과적합 방지가 가능하다.
- 분류와 회귀 둘 다 사용이 가능하다.
- 병렬 학습이 지원되도록 구현한 라이브러리다.
- XGBoost의 장단점은 아래와 같다.
- 장점
- 높은 예측 성능
- 빠른 속도와 확장성
- 강력한 특성 선택 가능
- 다양한 평가 지표 제공
- 단점
- 매개변수 튜닝의 어려움
- 자원 소모
- 해석이 어려운 모델
- 장점
- LightGBM

- XGBoost의 효율성 문제를 보완하여 나온 알고리즘이다.
- LightGBM의 장단점은 아래와 같다.
- 장점
- 학습하는 데 걸리는 시간이 적다.
- 메모리 사용량이 상대적으로 적다.
- gpu 학습을 지원한다.
- categorical feature들의 자동 변환과 최적 분할
- 단점
- 작은 dataset을 사용할 경우 과적합 가능성이 크다.
- 장점
- leaf wise tree 분할 방식으로 나무의 균형을 고려하지 않고 최대 손실 값을 가지는 leaf node를 지속적으로 분할해 깊고 비대칭적인 트리를 생성한다. 기존 트리 분할 방식에 비해 예측 오류 손실을 최소화할 수 있다.
- Catboost(Categorical Boosting)
- 상대적으로 최근에 나온 알고리즘으로 범주형 변수를 처리하는데 유용한 알고리즘이다.
- GBM의 문제인 과적합 문제를 해결하면서 동시에 학습 속도를 XGBoost과 LightGBM보다 빠르게 개선한 알고리즘이다.
- 기존의 GBM 알고리즘을 조작하여 타겟 누수를 개선했다.
- XGBoost과 LightGBM에서 Hyper-parameter에 따라 성능이 달라지는 민감한 문제를 해결하는 것에도 초점을 맞췄다.
- 특징
- Level-wise Tree
level-wise 방식으로 트리를 형성하지만 특징이 모두 동일하게 대칭적인 트리 구조로 형성한다. 이런 방식을 통해 예측 시간을 감소시킨다. - Ordered Boosting
Ordered Boosting은 기존의 부스팅 과정과 전체적인 양상은 비슷하되, 조금 다르다.
기존의 부스팅 모델이 일괄적으로 모든 훈련 데이터를 대상으로 잔차계산을 했다면 catboost는 일부 데이터만을 가지고 잔차계산을 한 후 모델을 만들어 나머지 데이터의 잔차는 이 모델로 예측한 값을 사용한다. - Random Permutation
데이터를 뽑아낼 때 셔플링하여 뽑아낸다. 또한, 모든 데이터를 뽑는 것이 아니라 그중 일부만 가져오게 할 수 있다. 이렇게 하는 이유는 과적합 방지를 위해 트리를 다각적으로 만들기 위해서다.
- Level-wise Tree
- Catboost의 장단점은 아래와 같다.
- 장점
- 다른 GBM에 비해 과적합이 적다.
- 범주형 변수에 대해 특정 인코딩 방식으로 인하여 모델의 정확도와 속도가 높다.
- 인코딩 작업을 하지 않고도 그대로 모델의 input으로 사용할 수 있다.
- 단점
- missing data를 처리해주지 않는다.
- 결측치가 매우 많은 데이터셋에는 부적합하다.
- 데이터의 대부분이 수치형인 경우 LightGBM보다 학습 속도가 느리다.
- 장점
스태킹(stacking)
여러 가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 예측 방법이다.
쉽게 말하자면 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점에서 배깅 및 부스팅과 공통점을 가지고 있지만, 가장 큰 차이점은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 점이다.
현실 모델에서 스태킹을 적용하는 경우는 많지 않지만, 캐글과 같은 대회에서 조금이라도 성능을 올려야 할 경우 자주 사용된다. 스태킹을 적용할 때는 2개에서 3개가 아닌 많은 개별 모델이 필요하고, 이렇게 적용한다고 해서 반드시 성능 향상이 된다는 보장은 없다. 일반적으로 좀 더 나은 성능 향상을 도출하기 위해 적용된다.
CV 세트 기반의 스태킹
CV세트 기반의 스태킹은 과적합 분제를 개선하기 위해 개별 모델들이 각각 교차 검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행한다.
진행 과정은 아래와 같다.
- 각 모델별로 원본 학습 / 테스트 데이터를 예측한 결괏값을 기반으로 메타 모델을 위한 학습 / 테스트 데이터를 생성한다.
- 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 데이터 세트를 생성한다.
- 개별 모델들이 생성한 테스트용 데이터도 전부 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 테스트 데이터 세트를 생성한다.
- 메타 모델은 최종적으로 생성된 학습 데이터 세트와 원본 학습 데이터의 레이블 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 데이터 세트를 예측하고 원본 테스트 데이터의 레이블 데이터를 기반으로 평가한다.

앙상블 학습의 장단점
장점
- 여러 가지 우수한 학습 모델을 조합해 예측력을 향상시킨다.
단점
- 모델 결과의 해석이 상대적으로 어렵다.
- 예측 시간이 많이 소요될 수 있다.
앙상블 학습법 코드 공부
https://github.com/DIB-PP/Machine-Learning
GitHub - DIB-PP/Machine-Learning
Contribute to DIB-PP/Machine-Learning development by creating an account on GitHub.
github.com
참고 자료
- https://casa-de-feel.tistory.com/8
- https://velog.io/@gangjoo/ML-%EB%B6%84%EB%A5%98-%EC%95%99%EC%83%81%EB%B8%94-%ED%95%99%EC%8A%B5-Ensemble-Learning%EA%B3%BC-%EB%B3%B4%ED%8C%85-Voting
- https://blog.naver.com/hajuny2903/222422472569
- https://velog.io/@dltnstlssnr1/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-5%EB%8B%A8%EA%B3%84%EC%95%99%EC%83%81%EB%B8%94-%EB%B3%B4%ED%8C%85%EB%B0%B0%EA%B9%85%EB%B6%80%EC%8A%A4%ED%8C%85%EC%8A%A4%ED%83%9C%ED%82%B9
- https://daebaq27.tistory.com/32
- https://blog.naver.com/winddori2002/221837065744
- https://blog.naver.com/winddori2002/221931868686
- https://mac-user-guide.tistory.com/79
- https://for-my-wealthy-life.tistory.com/24
- https://for-my-wealthy-life.tistory.com/35?category=950145
- https://colinch4.github.io/2023-09-07/10-32-36-460534/
- https://velog.io/@tjddls321/CatBoost
- https://hwi-doc.tistory.com/entry/%EC%8A%A4%ED%83%9C%ED%82%B9Stacking-%EC%99%84%EB%B2%BD-%EC%A0%95%EB%A6%AC
- https://velog.io/@sset2323/04-10.-%EC%8A%A4%ED%83%9C%ED%82%B9-%EC%95%99%EC%83%81%EB%B8%94
- https://semperparatus.tistory.com/74
- https://hye-z.tistory.com/28
'공부일기 > Machine-Learning' 카테고리의 다른 글
| 과적합(Overfitting)과 정규화(Regularization) (0) | 2024.07.28 |
|---|---|
| 교차 검증(Cross Validation) (0) | 2024.07.25 |
| 나이브 베이즈 분류기(Naive Bayes Classification) (0) | 2024.07.24 |
| 계층적 군집(Hierarchical Clustering) (2) | 2024.07.23 |
| K-평균 군집화(k-means clustering, K-Means) (0) | 2024.07.19 |